WebExtractor
WebExtractor allows you to easily define some Web page extracts, and to save the extraction definition.
The extraction definition can then be used in :
- custom application (initial application is personal bank account management)
- custom widgets
- etc... (synchro on palm in plucker or dedicated format, retrieving data for plotting...)
Web extracts are defined by :
- set of url to follow, possibly with parameters, possibly using key-chain stored values
- position in DOM tree, selecting by tag, id, and class, and possibly content
- some post procesing, e.g. converting to date, following links, etc...
A sample WebExtractSimpleViewer application can be used to retrieve web extracts, and a Cocoa widget plugin is now working, and is much more powerfull than javascript code generation, and is used in AuThéâtreCeSoir widget.
It also currently output some JavaScript code, allowing to fetch and retrieve extract, but this feature may not be kept.
Currently supported features:
Developers wishing to contribute can contact me- multiples URL/pages, multiples extraction per page
- partial editing of DOM extraction path
- recognition of DOM element containing month (thus will allow "click on current month" action)
- recognition/extraction of date, and date range
- operation on numeric extracted values
- integrated widgets
- bundle framework library
- array extraction
Sources are now on google-code
Screen shots
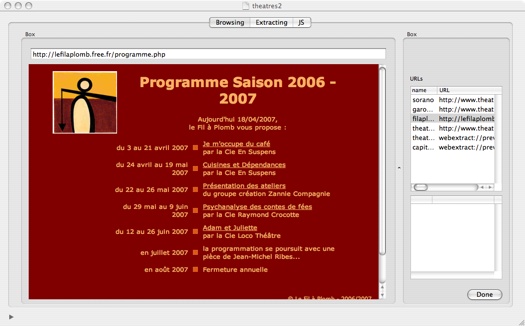
Browser mode
In browser mode, WebExtractor follows your action (click on link, etc..) and keep track of URLs
Extracts definition mode
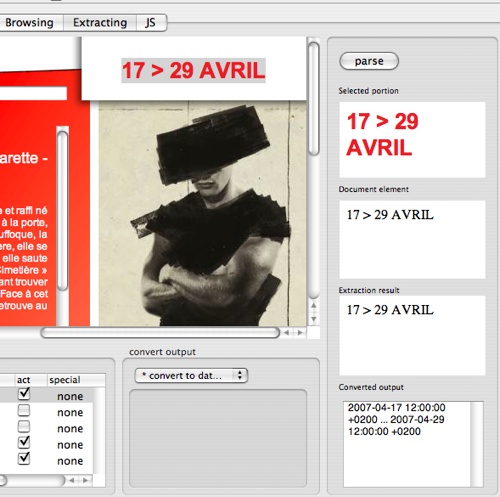
Versatile date parsing
WebClipper can recognise and convert dates or date ranges, from a variety of natural language format (e.g. "17 > 19 Avril", "Du 17/04 au 29/04", ...) , to NSCalendarDate objects.
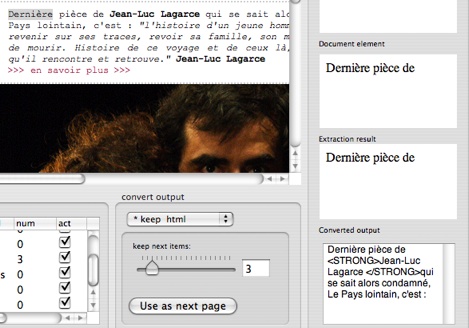
HTML output
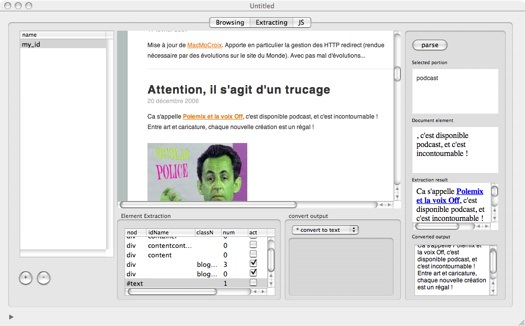
The selected extract is kept in HTML format. Following HTML elements can be kept too.
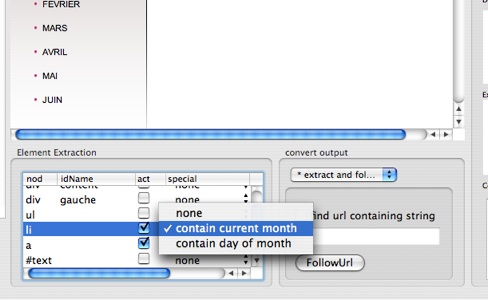
Follow url and HTML elements containing month or day
While specifying the HTML element to be extracted, WebExtractor automatically recognise that the element contain month name, and propose current month as the selection criteria (e.g.: use list element containing current month, instead of use 7th list element)
The extract can be itself an URL, and can be used for next page fetch.